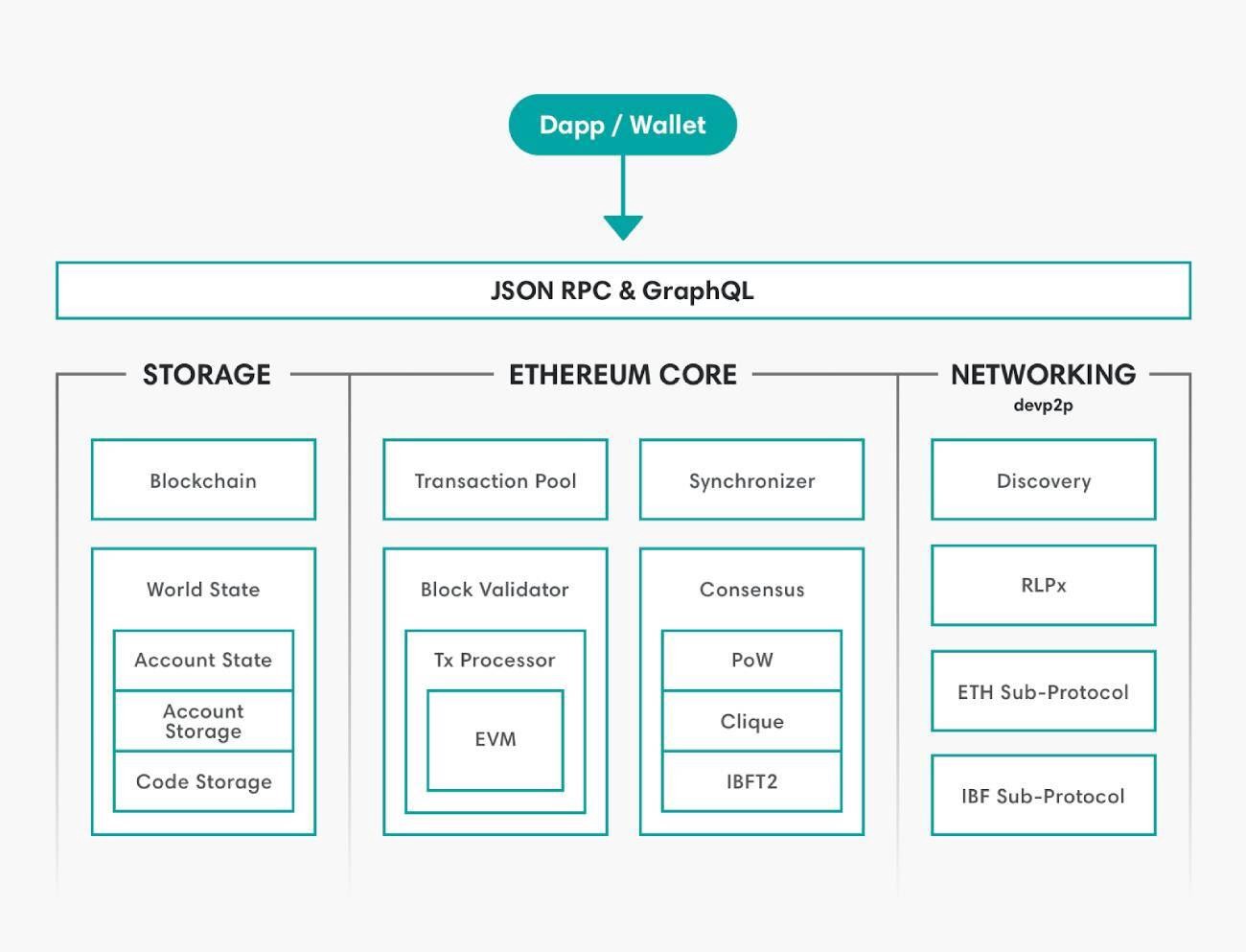
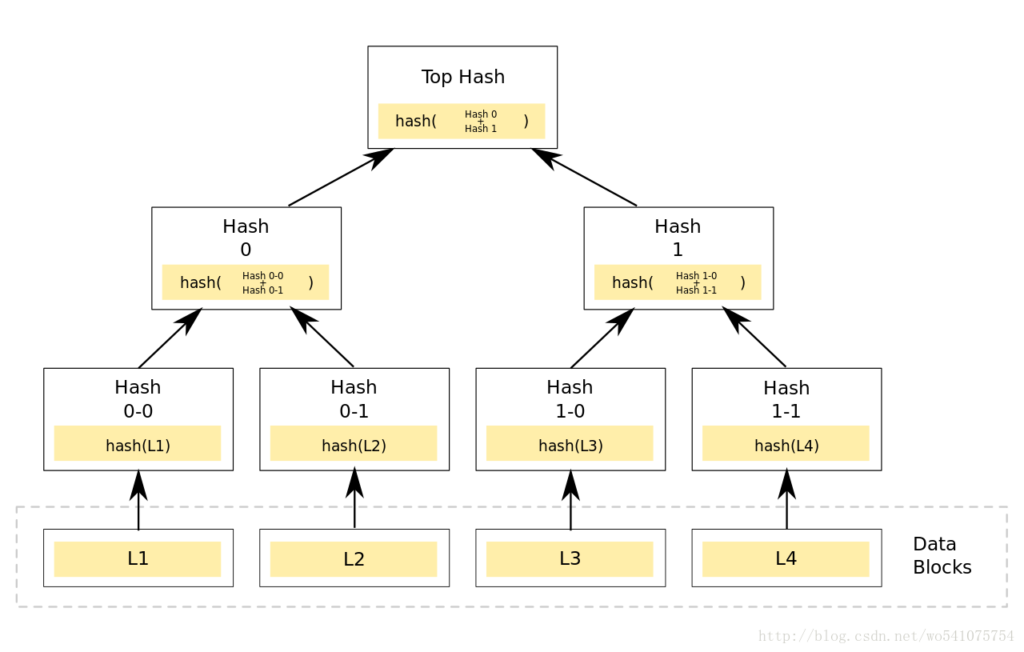
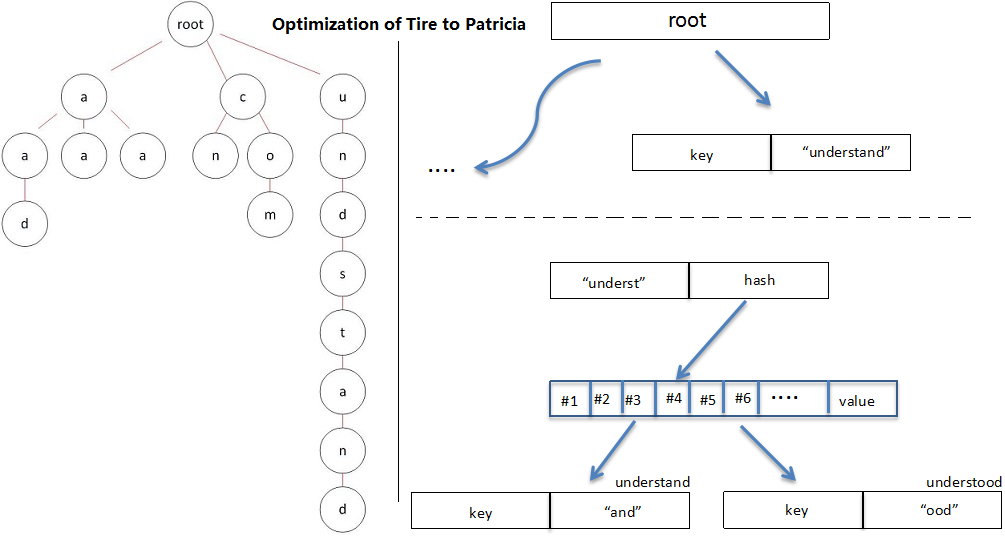
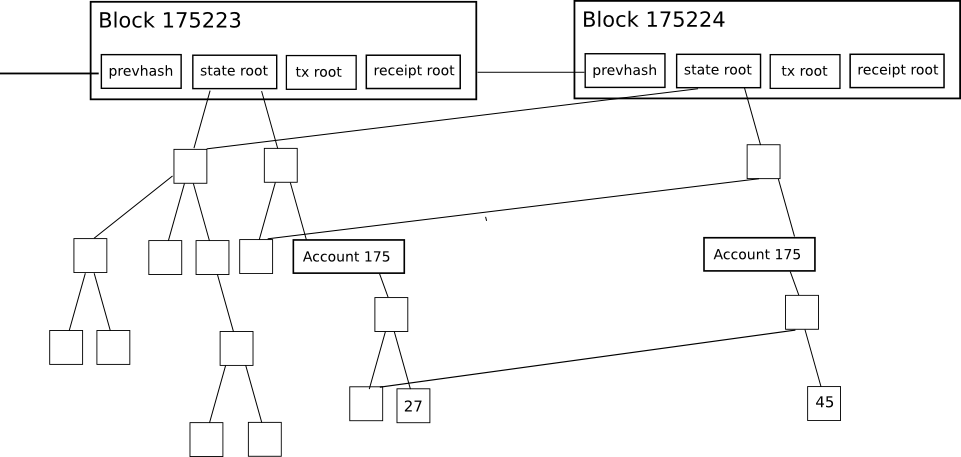
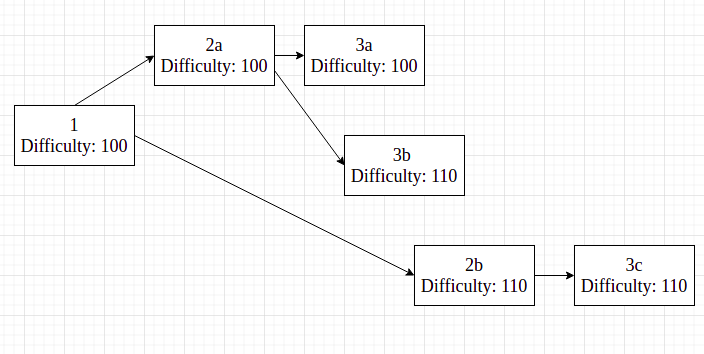
Go-ethereum (also known as geth) is the piece of code, written in Go, that secures the Ethereum network, a network that is valued at greater than $400 billion, and currently generates a daily revenue of 1000-2000 eth(~$35,000-45,000) for it’s miners, a significant portion of whom are using geth to mine. On top of that, decentralized applications on Ethereum cumulatively have more than $100 billion of assets locked, with millions of dollars moving through these applications on a daily basis. Let’s dive into the software that CANNOT afford to go wrong. So what exactly is geth’s relationship to the Ethereum we all know and love? In simple words, geth IS Ethereum (or more precisely, the Ethereum network is made up of a collection of nodes, some of which are running the geth code). Every transaction that is performed on the network is received, processed, and confirmed to be a part of the public ledger of Ethereum due to geth code (and other implementations of the Ethereum specification). You have most likely interacted with the Ethereum network on a dapp, via a wallet extension like Metamask. When you send a transaction, an RPC (Remote Procedure Call) call or a GraphQL query is made to a node on the Ethereum network. The node must be running an Ethereum client and as geth is the first and most widely used ethereum client, odds are your transaction will be received by a node running the geth code. The node consists of these 3 main components: Storage, Core and Networking and is further subdivided into many more components. We will be looking at 4 of these components that a normal transaction has to go through until it is considered to be confirmed on the Ethereum network. The first component that your transaction interacts with is networking, which includes connecting to fellow nodes on the network and transferring data to and from the nodes your node is connected to. Ethereum uses the devp2p library to cater to all it’s peer-to-peer networking needs, so that is what geth uses too. So, firstly your transaction will get added to the transaction pool of the node that you have made the call to, and it will gossip throughout the network via the peers that the node is connected to. Typically, miners will sort their own transaction pool according to gas price to maximize their earnings. So depending on your gas price, your transaction will be included in a block by a mining node that has either received your transaction directly or through any of its peers. Other than gossiping transactions throughout the network, the networking component of geth is also responsible for synchronizing a new node with the current state of ethereum. If a new node wants to join the Ethereum network with the intention of mining, it has to download the entire World State. There are 3 ways to download this data: There is another syncing method known as light sync, but a mining node cannot be a light node. A light node can not create blocks and it uses full nodes as intermediaries in a trustless manner to propagate its transactions throughout the network. Each full ethereum node has a local copy of the entire state of the Ethereum network. The database used to store all this information is levelDB, which is a fast on-disk key-value store. The data structure, on the other hand, is a Merle Patricia Trie. A Merkle Patricia Trie is actually a combination of 3 different data structures. Firstly, a Merkle Tree is a data structure in which each node stores the hash of it’s child nodes’ contents so any change in the content of the data would result in a different hash of the root of the tree, making any tampering of the data obvious. A trie (also known as a prefix tree) is a multi fork tree structure that is optimized for fast retrieval. The benefit of this data structure is that common prefixes can be reused, saving storage space. A Patricia trie is similar to a prefix trie, but improves on that by having the capability to store strings rather than just characters in a node if a set of characters serves as a prefix only once or rarely. To be more specific, there are actually 3 MPT trees that encapsulate all the data inside a particular block. These include: This is what a snippet of the Ethereum chain looks like. Each block header contains the root node of the 3 trees we have talked about, along with the hash of the previous block. To start off with processing a transaction, a mining node first performs some checks by performing the transaction on the current state to make sure there are no issues like incorrect nonce, insufficient funds to pay gas fee etc. It then does the same thing for all of the transactions for the block it is going to propose. But how exactly is a transaction processed? Ethereum transactions are written in a high level programming language (like Solidity or Vyper), which are then compiled to a bytecode that is what EVM (or the Ethereum Virtual Machine) understands. EVM is a stack based Virtual Machine similar to Java VM, .NET VM etc. The bytecode is a hexadecimal string, which can be further broken down into opcodes, which are 8-bit integers and act as instructions to the EVM. As EVM is a stack based VM, the opcodes/instructions are executed in a “Last in First Out” manner to perform state transitions during the course of executing a transaction. Each opcode costs a certain amount of gas and the total gas consumed by a transaction is simply a sum of the gas used by each opcode in a transaction. The node finally awards itself the coinbase reward (currently 2 eth). Now the block is ready to be propagated if the miner has managed to compute a nonce that, when concatenated with the hash of the block, results in a value less than the current difficulty target of the Ethereum network. The geth codebase has support for 2 consensus algorithms: ethash (implementation of Proof of Work) and clique (implementation of Proof of Authority). Mainnet ethereum uses Proof of Work, which is much more decentralized and trustless compared to Proof of Authority, which is used by various Ethereum test networks like Rinkeby, Goerli etc. Since we’re focusing on mainnet ethereum, we are only concerned with ethash. Ethash takes care of all the logic related to verifying nonces, calculating nonces etc. Finally, it’s time for the block to be validated by other miners. The block is propagated throughout the network just like transactions are propagated throughout the network by transferring data to and from connected peers. Block validation is performed by all the nodes that want to add this new block to their local copy of the Ethereum blockchain. An invalid transaction would do a miner no good because honest miners would fail to validate a block containing an invalid transaction and reject it. So unless the malicious miner owns a majority of the hashing power being used to mine Ethereum, the malicious block would be forked out of the canonical chain. Other than validating transactions, nodes will also validate the block header, which contains roots for the three Merkle Patricia Tries: State, Transaction, Receipt, nonce, and previous block hash. After all the validation checks have passed, a node will consider this new block a valid block and if this node now gets to mine the next block, it will build on top of this newly validated block. The true validity of a block is determined by how many blocks build on top of your block (also known as block confirmations). Furthermore, most PoW chains have something called the fork choice rule. As the name implies, it's the decision that a node has to make to vote for a particular fork/branch of the blockchain when there are multiple valid branches. This "voting" isn't explicit and is implicitly performed when a node decides to build on top of a particular branch/fork. Geth (and other Ethereum) implementations vote for or build on top of the branch which has had the greater hashing power used in mining it. This can be simply calculated by summing the difficulty level of blocks on a particular branch. So in the picture above, a node would consider the (1-2b-3c) chain to be the canonical chain and build on top of it since its cumulative difficulty is greater, proving that greater hashing power has been used to mine that chain. We have learned a lot about geth, but there are also other implementations of the Ethereum specification in different programming languages. Anyone can come up with their own implementation by following the official Ethereum specification. The reason behind the existence of multiple implementations is the essence behind Ethereum and other decentralized systems: avoiding a single point of failure. A programmer who’s up for the challenge is more than welcome to make a more time and space efficient implementation of the protocol, following all the rules and guidelines specified in the original Ethereum specification defined in the Yellow Paper, along with all the changes specified in the forks that have occurred uptil now. The major implementations other than geth include openethereum (Rust), erigon (Go), besu (Java), nethermind (C#). For a more in-depth analysis of the geth code, check out this awesome resource To look up interesting statistics about the current status of all the nodes in the Ethereum network, check out Ycharts Ethereum_Average_Transaction_Fee Also read: Ace Addresses And Signatures With Bitcoin Introduction
Components
Networking
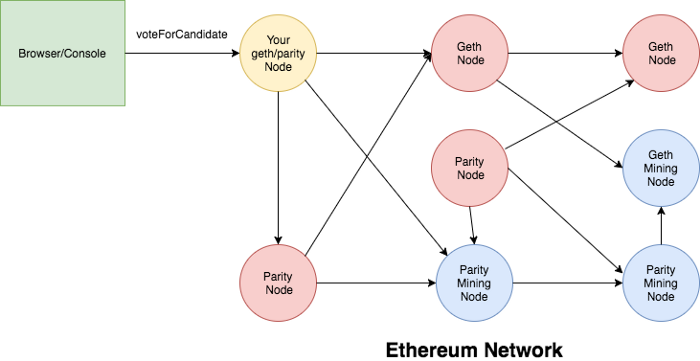
Syncing
Storage
EVM magic
Consensus
Fork Choice
Other implementations
Conclusion
References

We develop cutting-edge products for the Web3 ecosystem supported by our extensive research on blockchain core and infrastructure.

