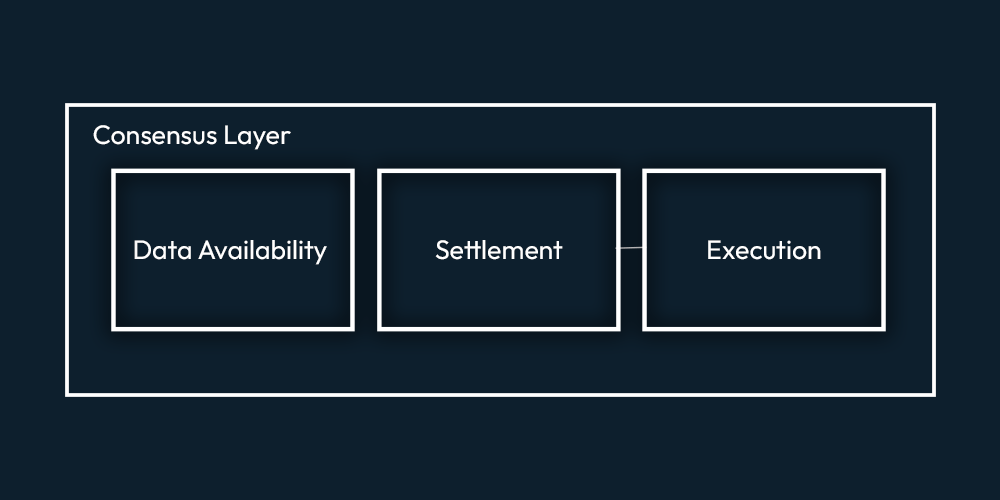
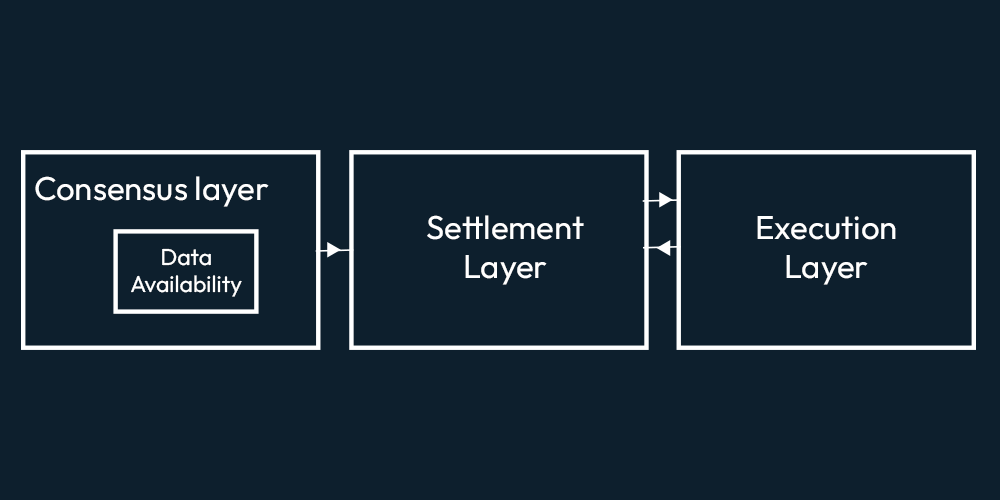
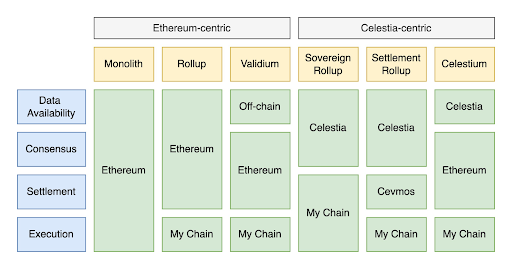
For the past few years, crypto tech has seen multiple blockchains rise to the horizon. The advent of these blockchains made the problems in the ecosystem prominent. One of these problems is data availability, which serves as a limitation to the systems. While multiple solutions have been coming forward, one particular solution, Celestia, is getting the spotlight. This publication deep dives into Celestia. Blockchains have been around for quite a while, with Bitcoin being in existence for the past 13 years. While Blockchains mainly consist of 3 functionalities, which namely are: Clarify the idea of modular blockchain with polynya’s blog. The way these functionalities are coupled together in the base layer of traditional blockchains is as follows. The problem which arises here is this approach limits the system because the monolithic blockchains have to validate the state of the blockchain. So it limits the throughput as well. If the blockchains minus the validity part from the things to worry about, that would be a shift towards a modular architecture for blockchains. That is what’s happening as the ecosystem is seeing a paradigm shift toward modular blockchains, with Ethereum moving towards a more modular blockchain. Celestia also makes use of modular architecture. In this architecture, the base consensus layer only takes care of data availability i.e., it makes data available but doesn't execute it. The settlement layer executes the transactions data on top of this base layer. And then, on top of it, there is a completely separate execution layer. These three layers make up the modular architecture of blockchains. As the base layer doesn’t have to deal with execution and settlement, it can have a higher capacity of Data Availability (DA) with the same resources as it focuses on only the DA part of the system. Similarly, the settlement and execution layer can provide a much better experience and much higher throughput as they are focusing or specializing solely on settlement or on execution. Now that the base layer is focusing on Data availability, it has to deal with the data availability problem. In Optimistic rollups (ORUs), Data availability is important because, without it, one cannot compute the fraud proofs to question sequencer's assertiveness; in case the sequencer misbehaves. In Ethereum, rollups post all data on the Ethereum chain and rely on Ethereum for data availability. Zero-knowledge Rollups (ZKRs) use validity proofs. They don't need data availability to check the block’s validity; however, the data must be available to know the state of the rollups. Celestia uses the modular approach for its architecture. Let's look at the three layers and how they function in the Celestia ecosystem. Let’s have a look at the components in a bit of detail in this section As mentioned above, when we refer to the execution layer in Celestia, we refer to rollups. The purpose of rollups is to execute transactions. Traditionally, for data storage, availability, and security rollups, use the L1 blockchains. The team of Celestia is internally focusing on optimistic rollups (such as optimism, fuel etc.) on top of the settlement layer. However, the settlement layer will be zk-rollups(such as zksync, starknet) compatible as well. As both ZKRs and ORs, are EVM compatible, so is the settlement layer. The execution layer may use its native tokens for gas fees or may even use EVMOS tokens. If a rollup on CEVMOS becomes congested, developers can spin up their own app-specific rollup on CEVMOS and create a trust-minimized bridge between them. The optimal settlement layer in Celestia is built using Celestia-EVMOS-COSMOS. Hence, we call it CEVMOS (pronounced as CEV-MOS). You can read Mustafa Al-Bassam’s CEVMOS’s proposal idea here. He describes CEVMOS as a rollup with trust minimized 2-way bridge, using a dispute resolution contract. Rollups or EVM Rollups can deploy to CEVMOS. CEVMOS will post all the data it is getting onto the DA Layer, also known as Celestia. As CEVMOS itself is a rollup, some censorship-resistant mechanism is required for sequencer selection. However, the details as to how this will be done are not clear yet. EVMOS tokens can be used to participate as a block producer. Celestia’s Virtual Machine doesn’t care about account balances, UTXOs, or contract data. Because all of that is required for execution purposes, and the Settlement layer is not concerned about execution. Having a separate DA layer is where things get interesting. In the Data availability layer, nodes will store the data in the same format that it receives data in from the settlement layer. Celestia token will be introduced to incentive the nodes storing the data. However, no clear Tokenomics are discussed till the time of writing this piece. Data is ultimately a combination of 0’s and 1’s, so, simply put Celestia’s DA Layer takes the 0’s and 1’s from the transactions and stores them in a block. Applications can fetch this data and run some VM (EVM/CEVMOS etc) over this, and make use of these transactions. The data availability layer in Celestia is coupled with the consensus. Consensus confirms the order of the blocks. In theory, blocks shouldn't be reorganized. Once you have a consensus, everyone has the same view of reality; that is how you prevent double standing. Everyone agrees that this is the canonical chain. For consensus the ecosystem uses Tendermint. Tendermint uses Byzantine Fault Tolerant (BFT) mechanism. We will not discuss the working of Tendermint here as that will be out of scope for this publication. Suppose Bitcoin blockchain is using Celestia. What would that look like? Bitcoin nodes will post the data of transactions taking place of the bitcoin blockchain to the Celestia DA layer, and every time the blockchain changes its state. It will get data from the DA layer, validate and compute its execution, and then post the data to the da layer. As there are no smart contracts in bitcoin so settlement layer is out of the picture. However, this will be the basic flow. In bridged blockchains, if a reorganization of blocks takes place on 1 side of the bridge and not the other side. Then someone can execute a trade to steal funds from the bridge. However, if we bring Celestia here. You’re posting the data of both blockchains to Celestia. Then the bridge won’t pay heed to the other blockchain, instead, it will get the state from Celestia. So then, in this case, you have to reorganize blocks on Celestia, which is not practical. But, if you do that, you’re essentially changing the history of all applications. Because one way to look at Celestia is it has all the data of any blockchain. So it is preserving the history of that blockchain. And the nodes in Celestia wouldn’t do that because they will be incentivized not to do that. Kind of like how Proof of work or proof of stake blockchains are incentivized to remain honest. This is share security and is the same for all applications. Blockchain has been rising with different primary focuses. Blockchains are not really designed with light clients in mind. Every blockchain has a set of validators that stores the essential data and provides the data when required. If you are not running the full node yourself, you may be running a light node or light client; then, it is not really secure. Because then you are relying on full nodes to get the data. A light client or light node is a piece of software that connects to full nodes to interact with the blockchain. Unlike their full node counterparts, light nodes don’t need to run 24/7 or read and write a lot of information on the blockchain. In fact, light clients do not interact directly with the blockchain; they instead use full nodes as intermediaries. The concept of light nodes in Celestia is essentially the same as Ethereum. The main difference here is in Ethereum the light nodes connect with full nodes to fetch data. So, they are trusting that the miners, they are getting data from, are honest. But if they are not doing things honestly then there is really no way for the light client to know, there is a chance of getting tricked and losing money. So, to be really secure, you will need a full node, which is not scalable. As running a full node with all EVM functionalities is expensive since you need a powerful computer to do that, a normal computer won’t cut it. If you want to create a model for a blockchain where some people run full nodes and there’s also a large number of people running trust-minimized light clients that use fraud or validity proofs, as these light clients don’t download the full block. Consider a scenario where a block producer produces a block but withholds the data from the full node. A light node asks a full node for data to which it replies that the block producer is withholding it. The light client then asks the block producer for the data, and in this scenario, the block producer provides the data. Now, the light node doesn't have a way to tell which node lied. The full node knows it is honest, the block producer knows it is not honest, but the light node might believe that the full node was dishonest when that was not the true case. How to avoid this from happening? Simply, light nodes should have the ability to determine whether data is available or not. Furthermore, it shouldn't depend on the full node for this. To do so, light nodes can download the block data, but then it is not a light node. Mustafa Al-Bassam, Alberto Sonnino, and Vitalik Buterin wrote formulized a solution for Fraud and Data Availability Proofs. The solution makes use of erasure coding. Erasure coding is used for error correction. It allows you to add redundant data. So that if some part of the data is missing or is corrupted, you can still reconstruct the original data. You increase the data size by adding redundant data and then the magic happens. Suppose there are 100 pieces of data in a block and you add 100 more pieces by making copies of the same data, it's turned into 200 pieces. Now, we have a malicious block producer, who wants to hide enough pieces of data so that the original data cannot be reconstructed. If we have 100 pieces of data, he will have to hide 1/100 pieces, whereas out of 200, he will have to hide 101 pieces. So 101/200 is close to half, while 1/100 is close to 0. You've turned a 100% problem into a 50% problem! So every time you sample data for availability, there is a 50% chance of being tricked. 25% chance of being tricked twice in a row. 12.5% for the third attempt and so on. The chance of you being tricked as you do more samples. But you cannot arrange data linearly. To make it secure, we need a 2D matrix of order n by n, with commitments on each row and column. The data is extended to retain the order of the matrix. So, the cost to sample this data would be O(√N). This means that the cost is proportional to the square root of the block size, it is not constant but you still don't have to download the full block. If a light client is sampling the data of 1MB, they will be downloading 1KB, if the data is of 1TB, the download size would be 1MB, and so on This is how Celestia is catering to the data availability problem for light nodes. Till now, we have discussed Celestia, i.e., the left side of figure 1. You should be able to sketch the architecture and working of Celestia, hopefully. However, now we have another unanswered question, which is, how does Celestia fit in with the existing blockchains? Learn about the two terminologies, intercluster and intracluster used in the figure in this blog. Figure 1 has Celestia Blockchain on the left side and on the right side, there is a hub that has all other blockchains, i.e. Cosmos, Ethereum, Solana connected to it. Since CEVMOS, Evmos and EVM are compatible, data transfer between them shouldn’t be a problem. The other existing blockchains can connect to Evmos and be part of the bigger picture. The number of L2s existing on Ethereum grew rapidly, so did the need for data availability solutions. The data availability solutions vary as they keep their data either on-chain or off-chain. All of them face a dilemma between cost and security. As solutions can keep data off-chain, making it less costly but then they have to introduce data availability committees, hence compromising security. OR they can put the data on chain however this solution is costly. While many solutions exist in The Ethereum Off-Chain Data Availability Landscape, we will have a look at Celestiums. Rollups currently interact with Ethereum’s consensus layer to post data and execution layer to provide proofs (validity/fraud proofs). Celestiums are L2 chains that use Celestia for Data Availability and Ethereum for settlement and dispute resolution. In other words, it will post its rollup block data to Celestia, Celestia will guarantee through Celestia’s consensus that data is available. Users too can verify through the Celestia protocol without having to download the full block. It will be done through data availability sampling, which we discussed above. It will also post fraud-proof or validity-proofs to Ethereum. How do we achieve this? Via the Quantum Gravity bridge, which is Celestia's data availability bridge contract. The Quantum Gravity Bridge has Rollup operators or L2 operators, which does two things. The first is it will produce the proof (left side of figure 2). Simultaneously, it will post the transactions data to Celestia’s DA Layer (right side of figure 2). Celestia’s validator set will attest to the availability of this data. But, anyone can run a node to check the data availability. The attestation is a Merkle root of the L2 data signed. These attestations or signatures are relayed to Ethereum, by the Quantum Gravity Bridge contract. The Quantum Gravity Bridge contract verifies the signatures on the DA attestation from Celestia. So when the L2 contract on Ethereum updates its state, rather than relying on the transaction data being posted as call data to Ethereum, it just checks to make sure the correct data was made available on Celestia by querying into the DA bridge contract. The bridge contract will return positive response for any valid attestation that has previously been relayed to it, otherwise, it will return a negative response.Blockchains and Modularity
Data Availability Problem in Rollups
The Modular Architecture In Celestia
Execution Layer
Settlement Layer
Data Availability Layer
Understanding Celestia with an example
Celestia and Shared Security
Nodes And Celestia
Erasure Coding
Extended Architecture
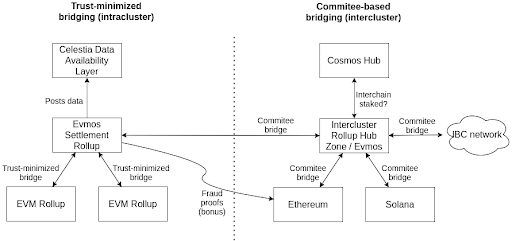
Celestia and Ethereum
Resources

We develop cutting-edge products for the Web3 ecosystem supported by our extensive research on blockchain core and infrastructure.


